Now that the community bonding period is over and the coding period has kicked off, as I had said in my previous post I would like to describe my project in detail.
Let me start from scratch.
Q: Under which Mentoring Organization will I be working in the summer?
A: I have been selected under LEAP Encryption Access Project. You may ask what does LEAP stand for in LEAP Encryption Access Project? Well, the name is recursive, like GNU, which stands for GNU’s Not Unix.
Q: What do they do?
A: LEAP is a non profit organization that aims to provide secure communications by providing a platform that is easy to set up and use. To quote the about section in their website,
LEAP’s approach is unique: we are making it possible for any service provider to easily deploy secure services and for people to use these services without needing to learn new software or change their behavior. These services are based on open, federated standards, but done right: the provider does not have access to the user’s data, and we use open protocols in the most secure way possible.
LEAP on the server side, deploys the LEAP platform and on the client side they provide a cross platform application - Bitmask.
LEAP provides secure and encrypted emails. One important point to note is that, if an incoming email is not encrypted, LEAP ensures that it gets encrypted such that only the intended recipient is able to view the original contents. Also, the server never sees plain text. The data is encrypted locally at the client’s machine and then made available for sync.
You may read more about LEAP here.
Q: What is the technology used behind the synchronization?
A: The core behind the entire synchronization process is SOLEDAD, which stands for Synchronization Of Locally Encrypted Documents Among Devices.
It is based on U1DB, which is used to synchronize databases of JSON documents. It is a database API that simplifies the entire sync mechanism.
Q: How does all this relate to my project?
A: As I had described in my previous post, U1DB uses plain old HTTP for the sync process. It uses a single POST request to update a document. This isn’t the best solution in terms of providing synced data for LEAP services.
Before proceeding any further, I would like you to look at the following diagram: (I had drawn this for my own understanding, but was too lazy to draw it on my computer.)
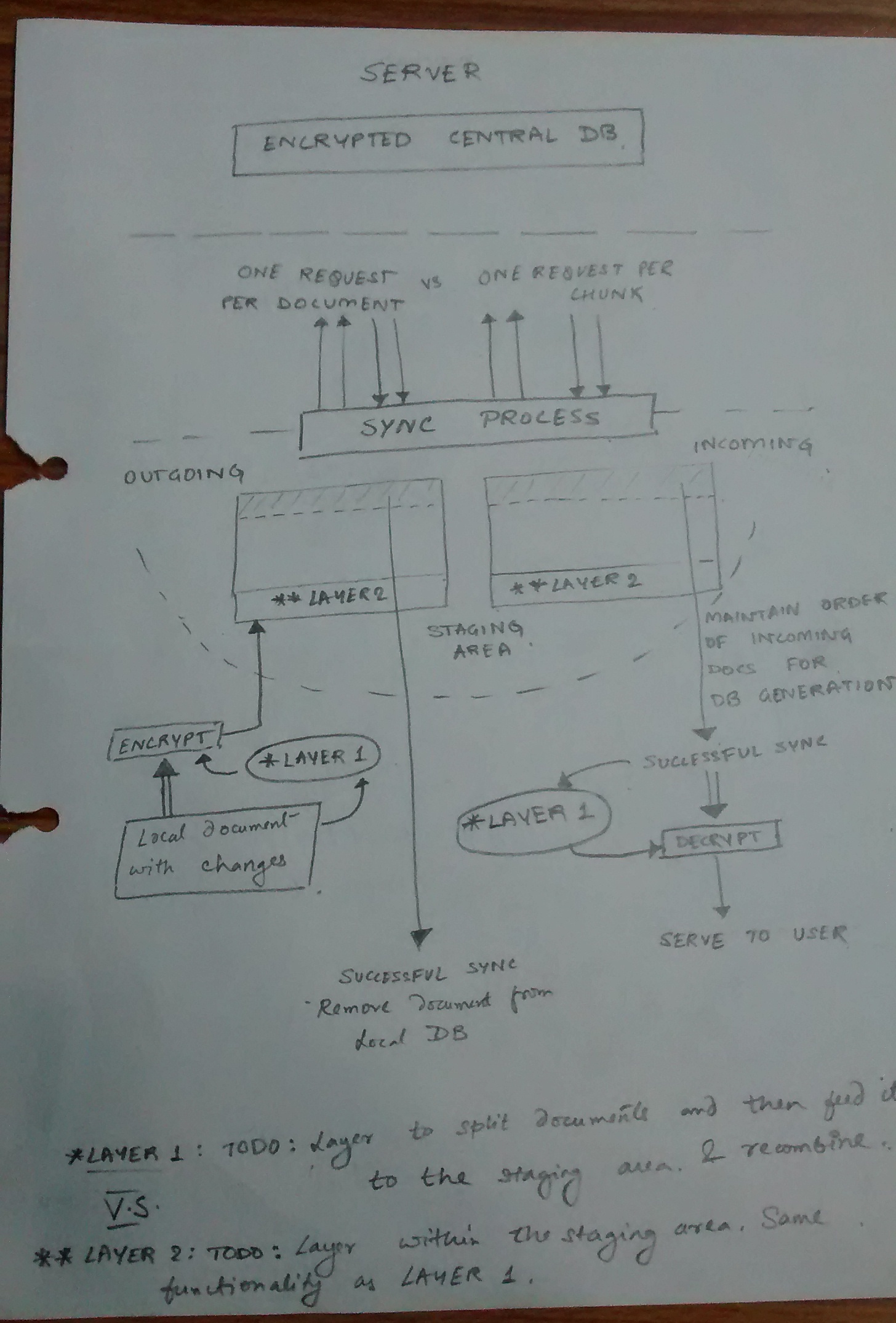
In the above image, if you look at the bottom of the image and start looking up,
- The user makes changes to the documents and it is encrypted and put into the staging area.
- The staging area is like a DB that represents the current sync state. When the document is put into the staging area, it is ready to be synchronized.
- The Layer 1 and Layer 2 both have the same functionalities. It is supposed to provide a seamless chunking layer, that will split the document into small chunks for synchronization. Note that this layer does not yet exist. We were debating where it should be ideal to place it. But after discussions with the community, my mentor feels it should be placed between SOLEDAD and U1DB. That way it will be easier to implement.
- The staging area will use the sync process provided by U1DB, which is currently implemented in HTTP.
- We are debating on splitting the entire sync request into One Request per Document vs One Request per Chunk. So in the coming days its going to be decided.
- After that, its pretty much synced into the central database.
- When the sync has been completed, the document is removed from the staging area.
For incoming requests,
- Incoming documents enter the staging area. Here the order of the incoming documents is important to be maintained for keeping in line with the db generation (This is a U1DB thing, something like an edit on an existing document. Save. Another edit on top of that.).
- Once the sync process is complete and the incoming documents have completely been received from the server, these documents will be removed from the staging area and made available for the user.
The diagram represents the state of the system somewhat a little into the future. Initially the document was being encrypted/decrypted within the sync process and the entire sync was being done in one single POST request, which was consuming a lot of CPU power and creating timeouts for large documents.
Currently work is being done on decoupling the enryption/decryption from the sync process and splitting the one huge POST request into smaller ones to avoid timeouts.
I have been talking about syncing documents. But these are not documents that the user creates on his/her own. Its a metadata document. That is it contains application information. So typically, the entire sync is for keeping in sync the same application across many devices.
Q: Where does my project fit in?
A: I am going to replace the HTTP sync process provided by U1DB. I have to keep all of the above when I am redesigning the entire sync protocol for ZeroMQ. There are somethings that I have to keep in mind:
- Maintaining Backwards Compatibility: I was talking with the ZeroMQ community, and came to know that ZeroMQ is not a neutral carrier. That is when it sents data onto the wire, it adds its own headers. Thus if ZeroMQ is handling HTTP data, then it won’t remain plain old HTTP anymore. ZeroMQ is going to make it into something that only a ZeroMQ endpoint will understand on the other end. However, the community did suggest using ZMQ_STREAM sockets for such a use case, but advised me not to use it as it is an ugly hack to talk to non-ZeroMQ applications on the other end of the wire. In short - DO NOT USE.
- Resume Sync: I need to support resuming a sync process by handling interruptions and not having to start the sync from scratch again.
- Selective Sync: One of the important things to do is that, the user should be able to sync selective documents.
Well, that’s it for now. I’ll post my progress at the end of this week. Once again, here’s my complete proposal.